モデルは生のインテリジェンスを提供しますが、ハーネスはそのインテリジェンスがどの程度効果的に適用されるかを決定します。 GitHub Copilot Agentic Harness は、GitHub Copilot SDK の単一の共有コンポーネントであり、GitHub と Microsoft 全体のさまざまなエクスペリエンス、さらには GitHub Copilot CLI、GitHub Copilot アプリ、Copilot コード レビューを強化します。ハーネスを改善すれば、あらゆる表面に恩恵がもたらされます。

ツール、コンテキスト、ワークフローはハーネスごとに整理されています。ハーネスは高速で、トークン効率が高く、開発者にとって予測可能である必要があります。それが、GitHub Copilot の Agentic Harness が行うように設計したものです。
この投稿では、幅広いエージェント ソフトウェア エンジニアリング タスクにわたる GitHub Copilot エージェント ハーネスの効率とパフォーマンスを実証するデータを紹介します。
ベンチマークをどのように反復するか
私たちは、公開ベンチマークと内部開発ベンチマークを組み合わせて、GitHub Copilot エージェント ハーネスの機能と効率を継続的に評価しています。当社の公開ベンチマークには業界標準が含まれていますが、多くの内部ベンチマークは GitHub や Microsoft 内の大規模なコードベースから派生しています。これを現実世界の指標とオンライン実験で補完し、制御された環境におけるハーネスのパフォーマンスと、エージェントによる問題解決とタスクの完了に対する実際的な影響を確実に理解します。
モデルプロバイダーのハーネスと比較して GitHub Copilot のハーネスのパフォーマンスを評価するために、できるだけ多くの変数を制御します。 同じモデルの 同じベンチマークタスクコンテキスト ウィンドウ、ロジック試行、ツール選択、MCP サーバー全体にわたって一般化されます。
以下に、4 つの主要モデルにわたって追跡したベンチマークのサブセットに関する最新の結果を報告します。 クラウドソネット4.6、 クラウド オーパス 4.7、 GPT-5.4そして GPT-5.5: :
| ベンチマーク | 作業エリア | 客観的 |
|---|---|---|
| SWEベンチ検証済み | オープンソースの Python リポジトリから人間が検証した 500 のバグ修正タスク | コーディングエージェントの確立された業界標準ベンチマーク |
| SWE-ベンチ プロ | より複雑なロジックと大規模なコード変更を必要とする、より困難な複数ステップのエンジニアリング タスク | 複雑な現実世界のソフトウェア エンジニアリング作業をより適切に反映 |
| スキルベンチ | エージェントがタスクを解決するためにスキルをどの程度効果的に活用しているか | 拡張性、スキルの使用法、トリガー機能を評価します |
| ターミナルベンチ | 端末ベースのタスクにおけるエージェントのパフォーマンス | 開発者が使用するコマンドライン ワークフローの有効性を測定します |
| ウィンヒル | Windows コンテナ内で実行されるタスクの内部ベンチマーク | オペレーティング システムおよび環境全体でパフォーマンスが正規化されていることを検証します |
総合的に比較してみると、 GitHub 副操縦士 cli これらのモデルをネイティブに出荷するモデル ベンダーのハーネスに対して: クラウドコード Sonnet 4.6 および Opus 4.7 の場合、および コーデックス CLI GPT-5.4 および GPT-5.5 の場合。
名目効率
いくつかのベンチマーク結果でモデルとタスクが固定されているため、GitHub Copilot ハーネスは、他のモデル ベンダーのハーネスと同等のタスク完了率を達成しながら、ほとんどの構成でトークン消費量が低くなります。
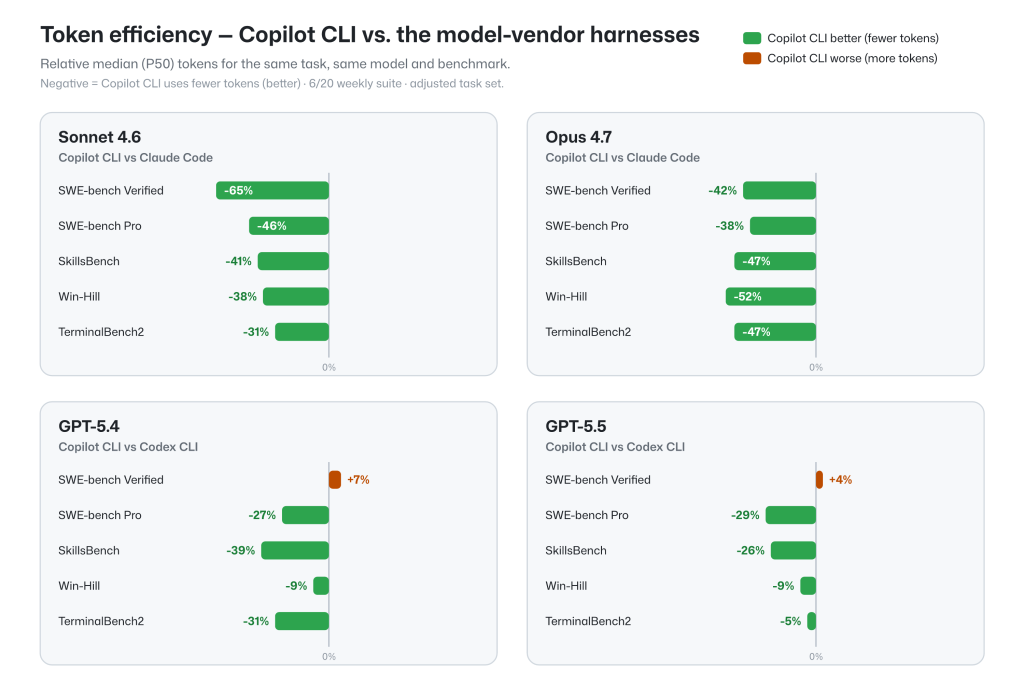
仕事の解決策
名目上の効率は、仕事が実際に完了した場合にのみ問題になります。
これらのベンチマークにおける GitHub Copilot エージェント ハーネスのタスク解決率は、固定モデルおよびベンチマーク タスクで使用した場合のモデル ベンダー ハーネスと同等です。これにより、マルチモデルの柔軟性、トークン効率、メモリおよび参照機能により、基礎となるモデルの可能性を最大限に活用できるようになります。
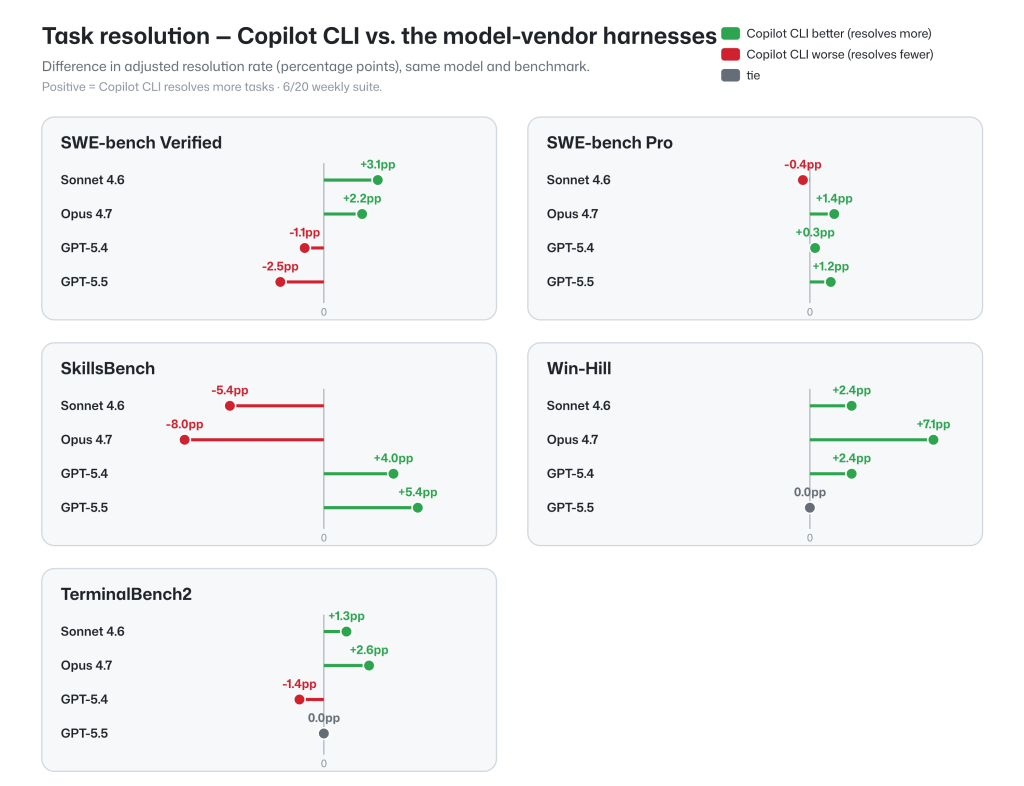
これらの結果は、モデルの確率的性質によりどの方向の違いも変動の範囲内に収まり、クロスハーネスのパフォーマンスが同等になるため、効果的なパリティを示しています。
TerminalBench: トークンの効率、タスクの完了および変動
タスクの完了とトークンの効率に関して GitHub Copilot Agentic Harness を継続的に改善するために、ベンチマークで詳細な分析を定期的に実行しています。以下は TerminalBench 2.0 での分散分析の例です。これは、タスクの完了とトークン効率に関する GitHub Copilot の強みだけでなく、このようなベンチマークに典型的な実行ごとの分散も強調しています。
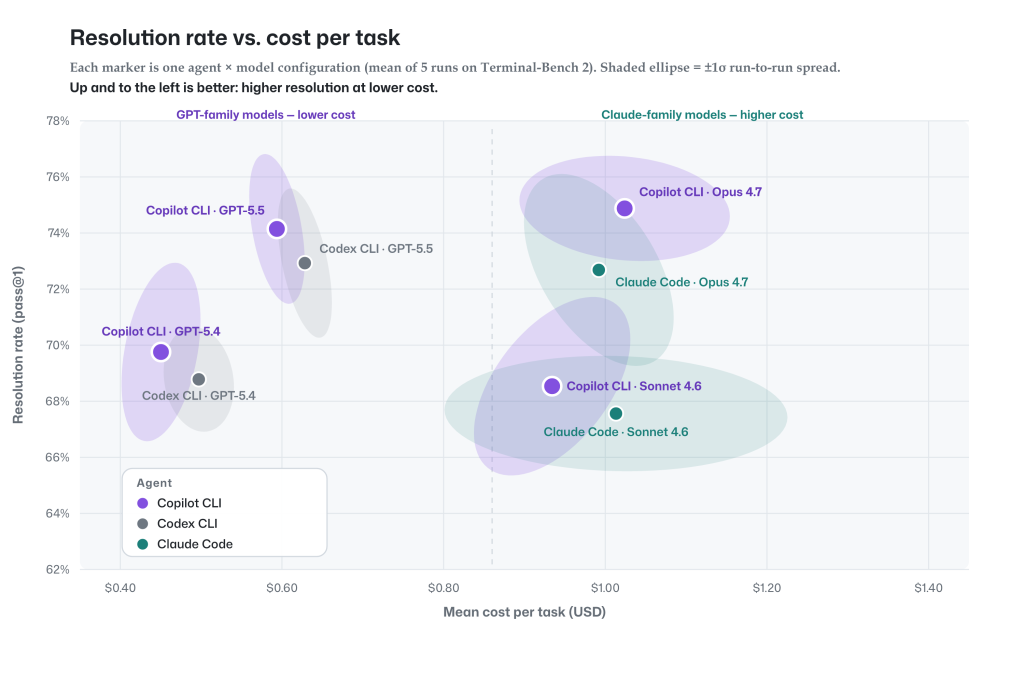
各マーカーは TerminalBench 2.0 上のエージェントとモデルの構成であり、縦軸は解決率、横軸はタスクあたりのドルコストです。各点の周りの影付きの楕円は、±1σ の実行ごとの広がりを示し、各構成が実行間でどの程度異なるかを示します。
次の 3 つのことが明らかになります。
- GitHub Copilot のエージェント ハーネスは、評価した構成におけるタスクの完了とタスクあたりのコストの点で、他のエージェントと同等かそれを上回っています。。紫色の (副操縦士) マーカーとその同じモデルの競合他社は、ほぼすべてのモデルで両軸の重複する楕円内に位置しており、差異は実行ごとの差異の範囲内にあります。 Co-Pilot は、完成度やコストの点で競合他社を下回ることがありません。
- 実行ごとの変動。各エージェントとモデルの組み合わせを少なくとも 5 回実行しました。楕円は、それらの実行の 1σ 広がりを示します。グラフの楕円が狭いほど、結果の再現性が高いことを意味しますが、楕円が広いほど、コストとタスクの完了の両方において、実行ごとに結果が変動することを示します。
- GitHub Copilot のモデルを選択する利点: このグラフは実際のトレードオフを示しています。GPT モデル (左) は最高の価値、つまり最低のコストでより強力な解像度を提供します。 Cloud Opus (右上) は、プレミアムで最高の解像度に達します。 GitHub Copilot では両方を考慮に入れているため、タスクごとに効率か最高の品質を選択できます。
1 つのハーネスで多くのモデルを使用可能
GitHub Copilot はエージェント ハーネスをサポートします 20 以上の限界モデル GPT、Cloud、Gemini、MAI ファミリだけでなく、オープンソース モデルやローカル モデルにも独自のキーを使用できます。各タスクの容量とコスト プロファイルに適切なモデルを選択することも、 自動車モデルの選択 自分で選択して、タスクの意図とモデルの健全性のバランスをとり、トークンの効率を最適化します。
マルチモデル アーキテクチャでは、単一モデル ベンダーのハーネスでは簡単に提供できないハーネス レベルの機能も利用可能になります。 ゴム製のアヒルたとえば、あるモデルが別のモデルの作業をレビューして、1 つのモデルだけで生成された結果を超える結果を改善する、モデルファミリーを越えた批評の使用です。
結論
ベンチマークは、多数のシグナルのうちの 1 つにすぎません。私たちは、各トークンを効率的に最大限に活用することに重点を置きながら、ベンチマーク、現実世界の使用指標、オンライン実験の品質を向上させるために常に取り組んでいます。
GitHub Copilot は、そのマルチモデル アーキテクチャを通じて、単一のモデルに縛られることなく、複数の構成で使用するトークンの数を減らし、主要なモデル ベンダーのハーネスに匹敵するタスク解決を提供します。開発者にとって、これは、タスクに最適なモデルを選択しながら、より低いトークンコストで同等の作業を達成できることを意味します。
自分で試してみてください
選択したモデルで GitHub Copilot を試し、毎日実行するタスクのアプローチを比較し、さまざまなモデルとエージェント戦略が環境でどのように機能するかを確認してください。
以下についてさらに詳しく学びます:
同じエージェント ハーネスがこれらのエクスペリエンスを強化します。私たちはその品質、効率性、柔軟性の向上を続けています。
方法論
可能な限り制御され、再現可能な比較を行うために、モデル、タスク、環境全体で同一の設定で各エージェントを実行します。
すべての実行には 2 時間のタイムアウトがあります。すべてのエージェントは、Web ツールが無効になり、すべてのツールが許可された状態で、非対話型でシングル ターンで実行されます。
ターミナルベンチ2の分析: デフォルト設定は、ロジック エフォートが中程度に設定されたエージェントに対して有効になります (例: クラウド コードのツール検索が有効で、Copilot CLI は github-mcp-server を使用します)。 Codex と Cloud Code は、直接 Anthropic および OpenAI エンドポイントを使用します。完全で信頼性の高い結果を保証するために、89 個の TerminalBench2 タスクすべての結果が返されるまで、データの欠落やインフラストラクチャ関連のエラーが再実行されました。モデルによって生成されたエラーは保持され、分析から除外されませんでした。各モデルは 5 回の独立した実行で評価され、Copilot は 2 つの個別の評価バッチでテストされ、クラウド コードおよびコーデックとの比較が可能になりました。
すべてのベンチマーク: すべてのエージェント モデル ペアは、同じコンテキスト ウィンドウ サイズ、同じ信号トークン制限、ロジック エフォート (中) および設定に正規化されています – デバイス検出なし、MCP サーバーなし。ハーネスのデフォルトの組み込みツールを維持します。公平な比較を確保するために、インフラストラクチャ関連の異常とネットワーク アクセスの影響はベンチマークのすべてのエージェントから除外されています。小規模なベンチマーク (サンプル数 100 未満) に対する実行ごとの変動の影響を最小限に抑えるために、5 回の独立した実行が実施され、最良の実行が報告されました。すべてのメトリックは pass@1 として表示されます。これらの一般化は、結果が公開ベンチマークの提出とは異なることを意味します。公開ベンチマークでは、通常、より高いロジック処理やその他の調整された設定が使用されます。
によって書かれた












Leave a Reply